User: | Open Learning Faculty Member:
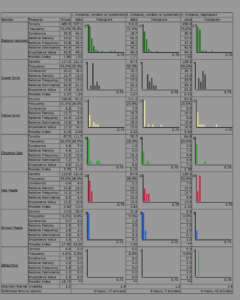
For this tutorial I used the distance-based methods for sampling in the Snyder-Middleswarth Natural Area. In looking at the results of the three different sampling methods used for this exercise, the fastest estimated sampling time came from using random sampling method.
1)Simple Random
- Eastern Hemlock- (537.1-469.9)/469.9 *100 =14.3%
- Sweet Birch – (121.6-117.5)/117.5 *100 = 3.5%
- Striped Maple – (30.4-17.5)/17.5 *100 = 73.7%
- White Pine = (0-8.4)/8.4 *100 = 100%
2) Systematic
- Eastern Hemlock = (310-469.9)/469.9 *100 =34%
- Sweet Birch = (87.4-117.5)/117.5 *100 = 25.6%
- Striped Maple = (31.8-17.5)/17.5 *100 = 81. 7%
- White Pine = (0-8.4)/8.4 *100 = 100%
3) Haphazard
- Eastern Hemlock = (490.4-469.9)/469.9 * 100 = 4.4%
- Sweet Birch = (129.5-117.5)117.5 *100 = 10.2%
- Striped Maple = (9.3-17.5)/17.5 * 100 = 46.9%
- White Pine = (9.3-8.4)/8.4 *100 = 10.7%
The most accurate sampling strategy for the most common species and least common species was haphazard sampling. For the second most common species the most accurate sampling method was simple random, and for the second least common species the most accurate was haphazard. In all three methods the accuracy dropped as species abundance dropped. Surprisingly, haphazard sampling appears to be the more accurate strategy in this situation. However, I do not understand why an estimated value would ever be exactly 0. Would there not always be a slight chance of the above species occurrence regardless of sampling method?