As previously discussed in Blog post 5, and small assignment 2, I collected data to help me understand the factors that influence the growth of bean plants specifically as observed at Duggan Community Garden. The hypothesis of my research is to determine whether the presence of other plants growing near an individual bean plant influences its growth and abundance; and therefore, due to greater plant diversity in garden plots reducing intra-specific competitions which would result in larger bean plants.
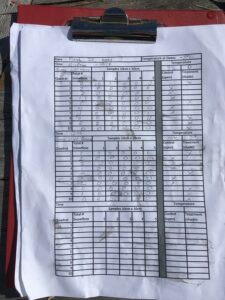
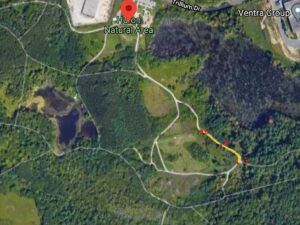
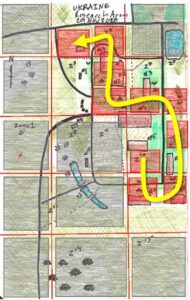
In this module, I completed all my data collection. I gathered data was from two different locations, which represents two different garden beds. Each garden bed area was about 5.56m2, 3.81 length, and 1.50m width. For both locations, I did 10 sample replicates. Each of the 10 sample units was 30cm away from the others to allow for independence of every single one of them.
One of the problems I faced, was that I was unable to collect data from the third location, as I had initially planned to do so. This was because of the inaccessible fence around this garden bed, I could not reach individual beans without making damage. Therefore, I decided to avoid any damage, and thus just collected data from only two locations.
The patterns observed have made me reflect on my hypothesis. I would not say that there is significance between the abundance of bean plants and the number of other types of plants growing nearby, but the data show a potential correlation. Also, I think my data is not sufficient to determine the significance of this relationship. However, I believe that I will be able to come up with a more developed conclusion once I analyze my data on a more detailed and deeper level, and when I read more literature about similar research.