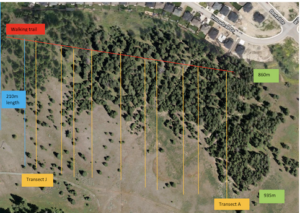
Collecting samples in the field has been fairly easy, so long as the proper amount of time has been allocated to collect them. In total, 450 replicates were taken using a 0.25m2 quadrat. These samples were taken randomly and in equal numbers throughout the three zone types as outlined in my experimental design; canopied forest, uncanopied forest, and open grassland. A total of 9 sampling regions were sampled, with 50 samples taken from each. Three of these regions were in open grassland, three were canopied forest, and three were uncanopied forest (Figure 1).
No major issues were encountered when implementing my sampling design (other than many mosquitos!).
So far, it appears that the grassland samples have a higher occurrence of Knapweed than in either of the forest zones; this would support my hypothesis that access to sunlight affects the growth frequency of Knapweed. Statistical analysis has yet to be done on the data.
age of image (google maps). Rough sampling zones outlined; 50 random samples taken per sampled zone. Project total n= 450.
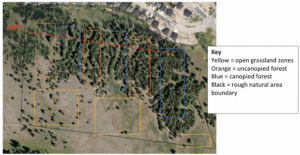
EDIT: A new data collection method was used following this blog post. 10 transects were sampled with 21 samples each, taken 10m apart along each transect (n=210). This new collection method cut the time needed to collect samples by a considerable margin. A 1m xx 0.5m quadrat was used to sample for presence/absence of Spotted Knapweed (Centaurea maculosa). See figure 2 for an updated design layout in the natural area to the South of residential Aberdeen, Kamloops.
Similarly, to the previous sampling method, grassland cover seems to have a higher frequency of Knapweed than either of the other two cover types. Data analysis still needs to be conducted to confirm the significance of this pattern.