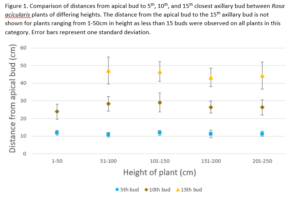
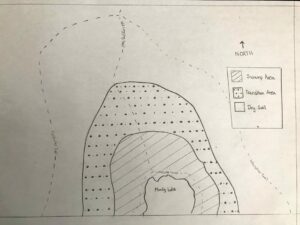
- Which technique had the fastest estimated sampling time?
Systematic sampling was the fastest since the sampling quadrants were relatively close to each other.
- Compare the percentage error of the different strategies for the two most common and two rarest species.
Systematic Sampling:
Two most common:
- Eastern Hemlock density was 469.9 stems/ha whereas the calculated density was 484.0 stems/ha.
The percent error = (484.0 – 469.9)/ 469.9* 100 = 3%
- Sweet Birch density was 117.5stems/ha whereas the calculated density was 108.0stems/ha.
The percent error = (108.0 – 117.5)/ 117.5* 100 = 8.1%
Two rarest species:
- Striped Maple density was 17.5 stems/ha whereas the calculated density was 16.0 stems/ha.
The percent error = (16.0 – 17.5)/ 17.5* 100 = 8.6%
- White Pine density was 8.4 stems/ha whereas the calculated density was 0.0 stems/ha.
The percent error = (0.0 – 8.4)/ 8.4 * 100 = 100%
Total time to sample: 12 hours, 37 minutes
Random Sampling:
Two most common:
- Eastern Hemlock density was 469.9stems/ha whereas the calculated density was 575.0 stems/ha.
The percent error = (575.0 – 469.9)/ 469.9* 100 = 22.4%
- Sweet Birch density was 117.5stems/ha whereas the calculated density was 129.2 stems/ha.
The percent error = (129.2 – 117.5)/ 117.5* 100 = 9.96%
Two rarest species:
- Striped Maple density was 17.5 stems/ha whereas the calculated density was 25.0 stems/ha.
The percent error = (25.0 – 17.5)/ 17.5* 100 = 42.9%
- White Pine density was 8.4 stems/ha whereas the calculated density was 4.2 stems/ha.
The percent error = (4.2 – 8.4)/ 8.4 * 100 = 50%
Total time to sample: 12 hours, 49 minutes
Haphazard Sampling:
Two most common:
- Eastern Hemlock density was 469.9stems/ha whereas the calculated density was 548.0 stems/ha.
The percent error = (548.0 – 469.9)/ 469.9* 100 = 16.6%
- Sweet Birch density was 117.5stems/ha whereas the calculated density was 120 stems/ha.
The percent error = (120.0- 117.5)/ 117.5* 100 = 2.1%
Two rarest species:
- Striped Maple density was 17.5 stems/ha whereas the calculated density was 4.0 stems/ha.
The percent error = (4.0 – 17.5)/ 17.5* 100 = 77.1%
- White Pine density was 8.4 stems/ha whereas the calculated density was 16 stems/ha.
The percent error = (16.0 – 8.4)/ 8.4 * 100 = 90.5%
Total time to sample: 12 hours, 55 minutes
- Did the accuracy change with species abundance?
The accuracy was lower for the rarest species when compared to the species that were more abundant.
- Was one sampling strategy more accurate than another?
Systematic Sampling was the more accurate method and Haphazard Sampling was the least accurate.