Previous data collection method
I used random.org for all my random number-generation. In my methods descriptions below, I will put the parameters for the generated number in brackets.
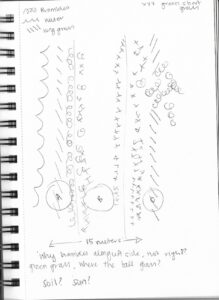
For my recent field observations, I decided to use simple random selection to choose sampling sites. I chose my starting point by walking 20 paces (10-30) north of the steps up to Volunteer Park. My process for determining the actual sample sites required me to be able to move in any direction, so it was important to have a starting point that was not on the edge of the beach.
Each new sampling site was chosen in a two-step process. I generated a number to indicate direction (1-4, where 1 = northwest, 2 = northeast, 3 = southwest, 4 = southeast), then generated a number of paces (5-15) to walk in that direction to take another sample. I repeated this procedure 10 times, more than the required 5, because the first five samples had no oysters at all (an early sign that the method would have to be modified).
At each sampling site, I recorded whether or not there was a large rock present (as a yes or no), and how many oysters I saw within the quadrat (oyster numbers broken down into two categories, attached and unattached).

Difficulties in implementing that sampling strategy
With my previous sampling strategy, each sampling site basically fell into one of four possible categories:

Almost all of my sampling sites were in the bottom right quadrant – they had neither rocks nor oysters. If I was seeking to measure the density of the oysters on the beach, those would be useful data points, but I am primarily interested in whether oysters are more likely to be near large rocks. Upon reflection, even the bottom left quadrant – rocks but no oysters – is not relevant either, because my question isn’t “are rocks more likely to have oysters nearby?” (which is superficially similar to “are oysters more likely to be near rocks?”).
I also was not leaving markers of where I had previously sampled, and my randomization method did not account for or prevent me from going back over previous areas. Since I was equally likely to go south or north, east or west, on average I was generally staying in the same place.

I diagrammed my movement using my notes, and it’s clear that some sampling sites were very close together. With more options for directions, eg. including north, south, east and west (so 1-8), I probably would have been less likely to ever immediately backtrack, but still equally likely to circle back to the same places. Although my previous strategy was random, I don’t think the sites were all sufficiently far apart to be independent.
Modifications to sampling strategy
Going forward, I will change how I randomize (for better independence) and what specific information I collect (to better address the research question).
Randomization
I will first measure out a section of the intertidal zone in paces, and then diagram it in my field journal. From there I can generate a set of x- and y-coordinates using random.org with the parameters I just measured. I’ll place those coordinates on my diagram in order, and eliminate any that are within a certain number of paces of a site that’s already on the map. I’ve drawn up an example of how this might look.

Data collection
At each sampling site, I will look for the nearest oyster. I will then record whether it is close to a large rock, or not. I believe this will better address the research question, because each oyster will be the sampling unit and the recorded information will then allow me to compare the number of oysters near rocks versus the numbers not near large rocks. To note any potentially confounding variables, I will also record whether that oyster is attached or not (in case attached oysters are more likely to be on rocks than unattached), and measure the oyster’s size.
Surprises in data collected so far
In the data I have already collected, using the previous sampling method, only four samples even had oysters present. Contrary to my expectations, half of the sampling sites that contained oysters did not have any large rocks. The most oysters found at one site (6) were found in a clear space without rocks.
I am not going to draw any conclusions from that information because, as discussed above, the method for collecting the data was flawed, and I don’t think four data points are sufficient.