Sampling Strategies
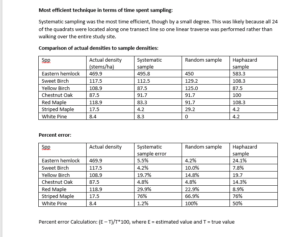
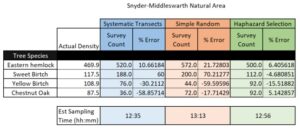
The sampling techniques used in the virtual forest tutorial were the systematic sampling, the random sampling, and haphazard sampling. The technique that had the fastest estimated sample time was the systematic sampling along a topographic gradient at 12 hours and 36 minutes. The random sampling took just a little bit longer at 21 hours and 43 minutes, and the haphazard sampling took the longest at 13 hours and 4 minutes. It is unsurprising that the systematic sampling took the least amount of time as the experimenter would be moving along as transect instead of wandering randomly around.
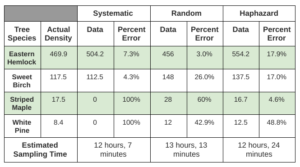
The percent error of the different strategies for the two most common species, Eastern Hemlock and Sweet Birch, and two least common species, the Striped Maple and White Pine, were as follows. The percent error for the Eastern Hemlock was 12.2% for the systematic sampling, 8.2% for the random sampling, and 10.7% for the haphazard sampling. The percent error for the Sweet Birch was 38.7% for the systematic sampling, 29.1% for the random sampling, and 32.8% for the haphazard sampling. The percent error for the Striped Maple was 8.6% for the systematic sampling, 4.6% for the random sampling, and 54.3% for the haphazard sampling. The percent error for the White Pine was 100% for the systematic sampling, 48.8% for the random sampling, and 100% for the haphazard sampling.
Table 1. Sampling Error (%) for the two most common and two least common species.
| Sampling type |
Eastern Hemlock |
Sweet Birch |
Striped Maple |
White Pine |
| Systematic Sampling |
12.2% |
38.7% |
8.6% |
100% |
| Random Sampling |
8.2% |
29.1% |
4.6% |
48.8% |
| Haphazard sampling |
10.7% |
32.8% |
54.3% |
100% |
The accuracy decreased drastically in situations where there were limited species, such as with the White Pine where systematic and haphazard samples had errors of 100%. This was not the case, however, for the Striped Maple where the percent error was very low for the systematic and random sampling, although it was high for the haphazard sampling. The accuracy likely increases with greater abundance as there are more samples and so a greater difference between estimated and actual is needed in contrast to limited samples where the existence or absence of a few samples can change the sampling error.
Overall the four species in Table 1, it appears that random sampling was more accurate than systematic sampling and haphazard sampling. Haphazard sampling was more accurate than systematic sampling where there was a greater population, but had a greater percent error for the Striped Maple and the sample percent error for the White Pine.